
c函数调用返回原理&&延迟绑定机制
前言
这周期中周,有四场期中考试,进度放缓了,博客搭了一整天,这周主要想把之前模棱两可的概念搞清楚,然后把所有难懂的原理从头开始写博客记录下来,看了PangBai分享的cyberangle的博客和星盟安全的前几节课,最大的收获是对c函数调用过程的原理和栈帧分析,以及got表和plt表的延迟绑定机制有了更深刻的认识,感觉看完cyberangle的博客后变的非常清晰。这周末考完期中考试会加快进度,争取五一前把格式化字符串结束掉。
c函数调用及返回的原理及栈帧分析
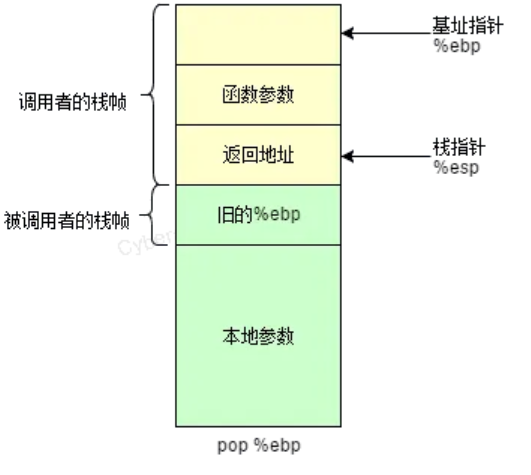
栈帧的概念:本质就是栈,用于保存函数调用过程中的参数,返回地址,本地变量等;分为栈顶(sp)和栈底(bp),其中栈顶地址最低,栈底地址最高;一般把bp到sp之间的区域当作栈帧;且整个栈空间有多个栈帧,每调用一个函数,就会生成一个新的栈帧。
首先函数调用分为调用者(调用函数的函数)和被调用者(在调用者函数里被调用的函数),调用者做的事情是1.将被调用函数的参数压入栈中和2.将返回地址压入栈中,被调用者做的事情是1.将调用者的rbp(ebp)压入栈,2.将rsp值赋给rbp,rbp就有了新的值,指向老rbp的栈空间,此时rbp也就成为了调用者函数的栈底。
简单来说调用函数就是通过push rbp再mov rbp,rsp (因为rsp现在指向的就是新push的栈空间的值也就是rbp的值) 来更新rbp的值,之后再用sub来开辟空间;

返回则与调用相反,通过mov rsp,rbp再pop rbp使得rsp栈顶先回到rbp的值再弹出到rbp寄存器内,最后ret**(相当于先将返回地址pop弹出并保存到eip中,然后处理器根据这个地址无条件地跳到相应位置获取新指令)**即可返回。
中间的elf文件保护机制和bss段,data段这些内容感觉没什么可说的,很好理解
GOT表和PLT表的延迟绑定机制
静态编译与动态编译
之前在csdn上看到一个非常好理解的例子类比静态编译与动态编译:小明要开一个餐馆(program)餐馆的菜单上有几百种菜肴(函数),小明的餐馆每天都会来很多顾客,每个顾客点的菜都可能不一样。我们知道,每道菜所需要的食材(系统函数)都不一样,这些食材都存放于仓库(动态链接库)中。
那么现在问题来了,小明如何保证每个顾客点的菜都能被满足呢?
第一种方式:
小明把仓库中所有的食材都搬进厨房(静态编译)
这时,小明不需要挪地方(静态)只需要在厨房中就可以工作,但是这会带来冗余,可能厨房中的食材很多都用不上。
第二种方式:
小明每次遇到新的所需要的食材,才去仓库取(动态编译)
这时,小明可能挪动的比较频繁(动态),但是可以保证厨房里面没那么多可能用不到的东西。
静态编译
一个程序运行过程中可能会调用许许多多的库函数,这些库函数在一次运行过程中不能保证全部被调用。
静态编译的思路就是将所有可能运行到的库函数一同编译到可执行文件中
这一方式的优点就在于在程序运行中不需要依赖动态链接库。适用的场合就是比如你本地编译的程序需要的动态链接库版本比较特殊,如果在别的机器上运行可能对方动态链接库版本和你不一样会出bug,这时候用静态编译。
缺点就是编译过后程序体积很大,编译速度也很慢
动态编译
一个程序运行过程中会调用许许多多的库函数,这些库函数在一次运行过程中不能保证全部被调用。
动态编译的思路就是逢山开路,遇水架桥,直到遇到需要调用库函数的时候再去动态链接库中寻找
所以其优点之一是缩小了执行文件本身的体积,另一方面是加快了编译速度,节省了系统资源
缺点一是哪怕是很简单的程序只用到了链接库里的一两条命令,也需要附带一个相当庞大的链接库;二是如果其他计算机上没有安装对应的运行库,则用动态编译的可执行文件就不能运行。
延迟绑定
我们再回去看看小明:小明说我选择第二种方式(动态编译)
但是小明餐馆开业后发现搞不赢,每次都要去仓库找,太麻烦了
于是乎,小明想到:每次我遇到新的食材,我就去仓库找,但是每次找完,我就在小本子(got表)上记录这个食材的地址,这样下一次找就快很多了!
而存放这个地址的小本子就是got表。
这就是linux的延迟绑定机制,got表全称是Global Offset Table,也就是全局偏移量表。
在程序运行时,got表初始并不保存库函数的地址,只有在第一次调用过后,程序才将这一地址保存在got表中。
原文链接:https://blog.csdn.net/2301_80361487/article/details/140247371
下面这两张张图(分别为第一次调用和第二次调用)就很好理解了


首先不管是第几次调用外部函数,程序真正调用的其实是plt表,第一次调用时got表中还没有存储函数地址,回到plt表头经过一系列过程进行函数真实地址解析,解析后将函数地址填入got表中;第二次调用时got表中已经存储了目标函数地址,直接跳转即可。